Architecture
Overview
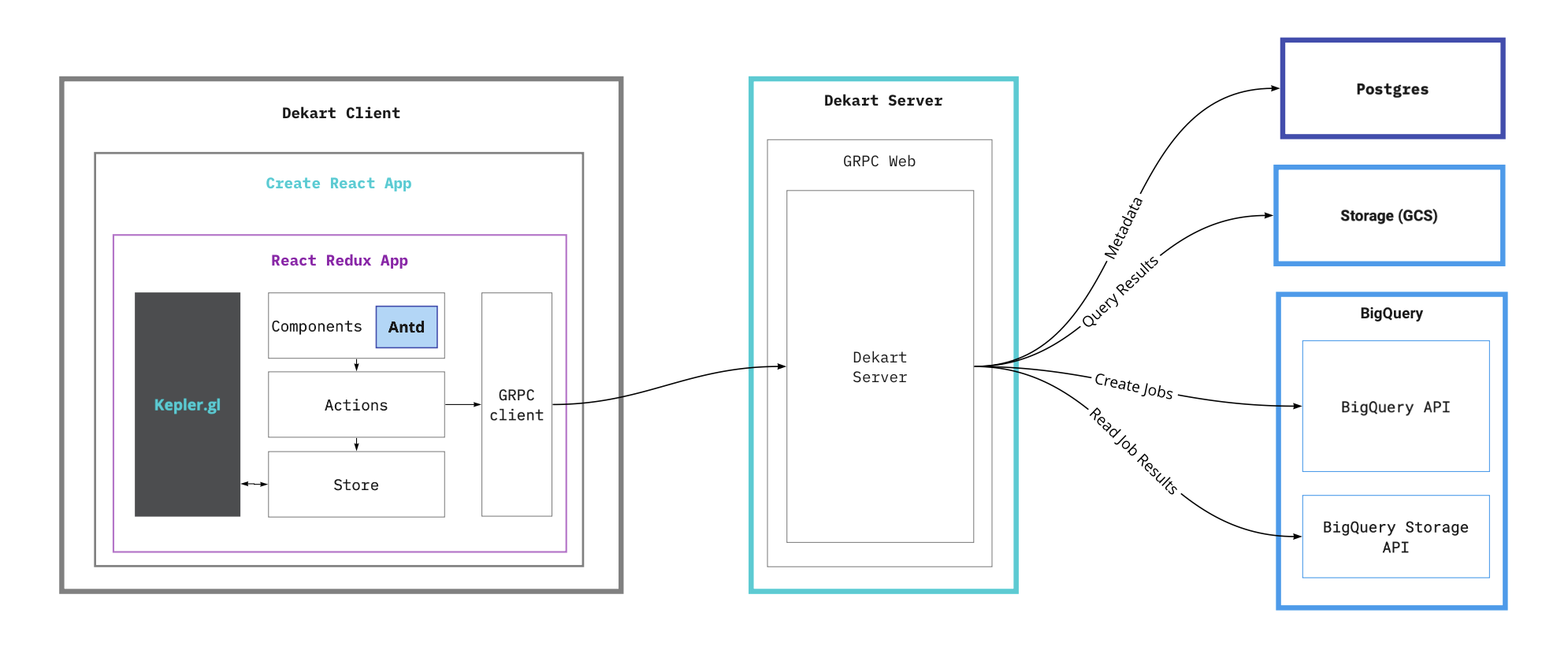
Client
Dekart Client is based on Create React App project setup, javascript Redux application utilizing Actions and Store. Components are build on top of And Design components framework.
Keplrer.gl (fork) is used to render maps and configure visualizations. It is integrated via redux actions
Communication with server is happening via GRPC. Query results are fetched via HTTP in CSV format.
Server
Server is a golang application. API is based on GRPC and described in proto file. Browser support is implemented via grpc-web package.
GRPC Server Streams are using long pull pattern for backwards compatibility with proxies and load balancers:
- client subscribes on stream and waits for the first message
- server sends messages and immediately closes a stream
- client receives message and reopens stream
see client implementation details
Service Dependencies
Postgres Database
Is uses to store query metadata:
- Dekart report ids
- SQL queries associated with report
- BigQuery Job ids
- Kepler Map Configuration
Google Cloud Store
Is used to store query results
BigQuery
Is used to perform queries on datasets. Once Job is ready data is fetched from BigQuery and stored on GCS.
BigQuery Query Flow
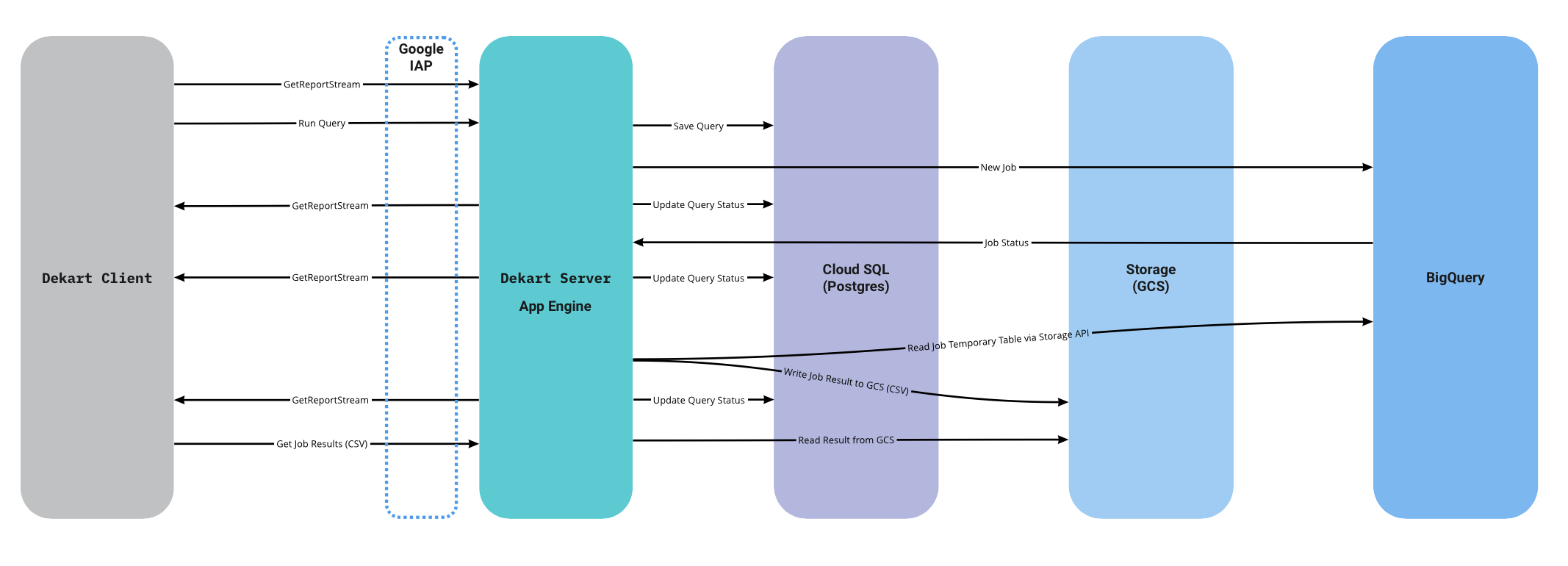
This diagram explains BigQuery query flow step by step:
- Client subscribes on Report GRPC Stream to watch all report updates. Multiple clients can subscribe on report and will see synchronized status.
- Client sends
RunQuerycommand (unary GRPC call) - Server updates report status in Postgres DB and starts BigQuery Job
- Server waits for BigQuery Job to complete
- Once Job is Ready Server fetches Job Results and streams it to Google Cloud Storage
- Once Result is saved in Cloud Storage update with result id is received by the client
- Client requests result by separate HTTP endpoint from server
Google IAP (Identity Aware Proxy) is supported to authenticate user requests.